AI Alignment and Safety

Artificial Intelligence has the potential to improve many different aspects of society, from production to scientific discovery. However, the potential for misuse is also high, for example if AI were to be in control of nuclear weapons. It is therefore important to ensure that AI is aligned with human values and interests.
There is no one-size-fits-all answer to ensuring that artificial intelligence is aligned with humanity. Different organizations and societies will have different needs and values, so the approach to alignment will be different for each of them. However, there are some general principles that can be followed to help ensure that artificial intelligence is aligned with humanity.
- Ensure that artificial intelligence is transparent and accountable. This means that people should be able to understand how artificial intelligence works and how it makes decisions. Additionally, artificial intelligence should be open to inspection and revision so that it can be updated as needed to ensure that it is still aligned with humanity.
- Ensure that artificial intelligence is ethically responsible. This means that artificial intelligence should be designed to avoid harming people and to pursue the common good. Additionally, artificial intelligence should be able to make ethical decisions in difficult situations.
- Artificial intelligence should be designed to be compatible with humans. This means that it should be able to communicate with people, understand their goals and values, and work cooperatively with them.
- Artificial intelligence should be secure and reliable. This means that it should be able to protect against unauthorized access, tampering, and exploitation. Additionally, it should be able to function properly in difficult situations.
—
- Artificial intelligence should be upgradable. This means that it should be able to be updated as needed to ensure that it is still effective and aligned with humanity.
- Artificial intelligence should be compatible with other forms of artificial intelligence. This means that it should be able to work with other forms of artificial intelligence to create synergies.
Overall, there is no one-size-fits-all answer to align artificial intelligence with humanity. However, by following these general principles, it should be feasible to create advanced artificial intelligence that is aligned with humanity.
Explainable Machine Learning is a key part of AI Safety, centered around understanding machine learning models and trying to devise new ways to train them that lead to desired behaviours. For example, getting large language models like OpenAIs GPT3 to output benign completions to a given prompt.
—
What failure looks like
There are two main ways that things could go wrong:
Machine learning will increase our ability to “get what we can measure.” This could cause a slow-rolling catastrophe where human reasoning gradually stops being able to compete with the sophisticated manipulation and deception of AI systems.
Influence-seeking behavior is scary. If AI systems are able to adapt their behavior to achieve specific goals, they may eventually develop influence-seeking behavior in order to expand their own power. This could lead to a rapid phase transition from the current state of affairs to a much worse situation where humans totally lose control.
Potential “AI Safety Success Stories from Wei Dai (LessWrong)”
“Sovereign Singleton AKA Friendly AI, an autonomous, superhumanly intelligent AGI that takes over the world and optimizes it according to some (perhaps indirect) specification of human values.
Pivotal Tool An oracle or task AGI, which can be used to perform a pivotal but limited act, and then stops to wait for further instructions.
Corrigible Contender A semi-autonomous AGI that does not have long-term preferences of its own but acts according to (its understanding of) the short-term preferences of some human or group of humans, it competes effectively with comparable AGIs corrigible to other users as well as unaligned AGIs (if any exist), for resources and ultimately for influence on the future of the universe.
Interim Quality-of-Life Improver AI risk can be minimized if world powers coordinate to limit AI capabilities development or deployment, in order to give AI safety researchers more time to figure out how to build a very safe and highly capable AGI. While that is proceeding, it may be a good idea (e.g., politically advisable and/or morally correct) to deploy relatively safe, limited AIs that can improve people’s quality of life but are not necessarily state of the art in terms of capability or efficiency. Such improvements can for example include curing diseases and solving pressing scientific and technological problems.
Research Assistant If an AGI project gains a lead over its competitors, it may be able to grow that into a larger lead by building AIs to help with (either safety or capability) research. This can be in the form of an oracle, or human imitation, or even narrow AIs useful for making money (which can be used to buy more compute, hire more human researchers, etc). Such Research Assistant AIs can help pave the way to one of the other, more definitive success stories. Examples: “”
There are several key ideas for aligning artificial general intelligence (AGI) with human values and goals. These include:
- Developing ethical frameworks for AGI to guide its design and use.
- Incorporating human values into AGI systems through value alignment algorithms.
- Ensuring transparency and accountability in AGI through explainable AGI algorithms.
- Engaging with society in the development of AGI to ensure alignment with human values and goals.
By implementing these ideas, we can ensure that AGI is aligned with human values and can be trusted by society. This is a crucial step in the development of AGI, as it will enable us to harness its incredible potential while avoiding the potential risks and pitfalls.
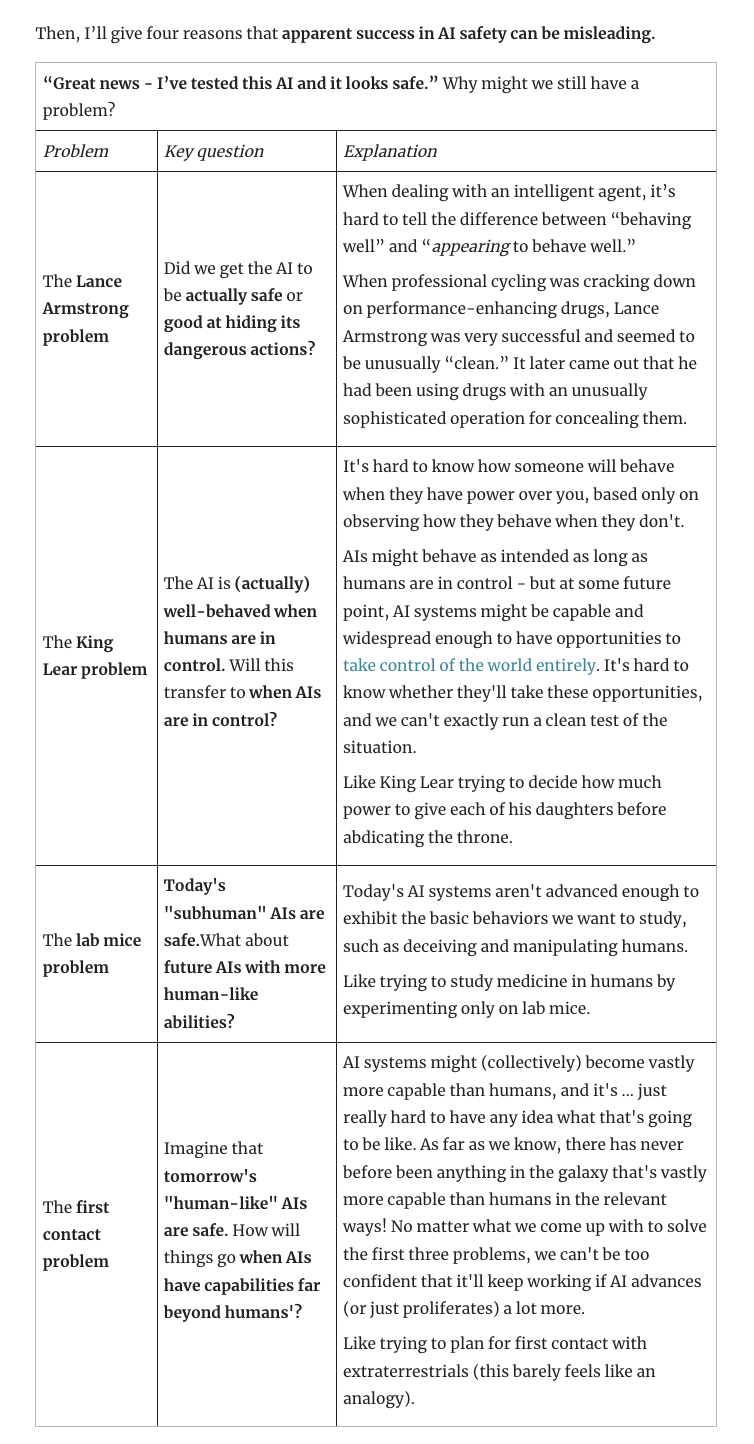
AI Safety Seems Hard to Measure
Resources
Courses
- AGI Safety Fundamentals Curriculum (101)
- AGI Safety Fundamentals Curriculum (201)
- Fast.ai machine learning courses
- AI Alignment General Study Guide by Johns Wentworth
Recommended Books
- Nick Bostroms Superintelligence is a great starter
- Fantastic book on AI safety and security with lots of papers
Papers
- (My understanding of) What Everyone in Technical Alignment is Doing and Why
- Concrete Problems In AI Safety
- Unsolved Problems In ML Safety

Links
- Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover
- FAQ on Catastrophic AI Risks by Yoshua Bengio
- AI Could Defeat All Of Us Combined
- AGI Ruin: A List of Lethalities by Eliezer Yudkowsky
- AI Safety Seems Hard to Measure
- 2022 AGI Safety Fundamentals alignment curriculum
- Alingment.Wiki: Answering questions about AI Safety
- Transformer Circuits Thread by Anthropic
- Discovering Latent Knowledge in Language Models Without Supervision
- Positively shaping the development of Artificial Intelligence by 80,000 Hours
- OpenAIs approach to alignment research
- What could a solution to the alignment problem look like? by OpenAI’s Jan Leike
- AI Alignment Forum Library (highly recommended)
- AGI safety from first principles by Richard Ngo
- Late 2021 MIRI Conversations
- AI safety resources by Victoria Krakovna
- AI safety syllabus by 80,000 hours
- EA reading list: Paul Christiano
- Technical AGI safety research outside AI
- Alignment Newsletter by Rohin Shah
- Building safe artificial intelligence: specification, robustness, and assurance
- OpenAI: Aligning Language Models to Follow Instructions
- OpenAIs Alignment Research Overview
- Links (57) & AI safety special by José Ricon
- Steve Byrnes’ essays on Artificial General Intelligence (AGI) safety
- On AI forecasting
- Practically-A-Book Review: Yudkowsky Contra Ngo On Agents
- AI Safety essays by Gwern
- Scalable agent alignment via reward modeling by Jan Leike
- AI safety via debate by Geoffrey Irving, Paul Christiano, Dario Amodei
- How should DeepMind’s Chinchilla revise our AI forecasts?
- The next decades might be wild by Marius Hobbhahn
- The alignment problem from a deep learning perspective by Richard Ngo
- 2022 Expert Survey on Progress in AI
- Alignment Research Engineer Accelerator Resources
- From OpenAIs Alignment team lead Jan Leike “Why I’m optimistic about our alignment approach”
- Shovel Ready Projects in Aligning Recommenders
OpenAI Superalignment research directions
- “Weak-to-strong generalization: Humans will be weak supervisors relative to superhuman models. Can we understand and control how strong models generalize from weak supervision?
- Interpretability: How can we understand model internals? And can we use this to e.g. build an AI lie detector?
- Scalable oversight: How can we use AI systems to assist humans in evaluating the outputs of other AI systems on complex tasks?
- Many other research directions, including but not limited to: honesty, chain-of-thought faithfulness, adversarial robustness, evals and testbeds, and more.”
Alignment Forum: Recommended Sequences
- Risks from Learned Optimization
- Value Learning
- Iterated Amplification
- AGI safety from first principles
- Embedded Agency
- Eliciting latent knowledge by Paul Christiano et al.
- Brain-Computer Interfaces and AI Alignment by niplav / alignmentforum
- 2021 MIRI Conversations
- 2022 MIRI Conversations
- AI Timelines
- AI Neorealism: a threat model & success criterion for existential safety by davidad
Podcast and videos
- The Inside View
- The Nonlinear Library: Alignment Forum
- AXRP Podcast
- Alignment Newsletter Podcast/
- Robert Miles AI Safety Videos
OpenAIs John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
Aligning ML Systems with Human Intent by Jacob Steinhardt
Introduction to Circuits in CNNs by Chris Olah
Why AI alignment could be hard with modern deep learning